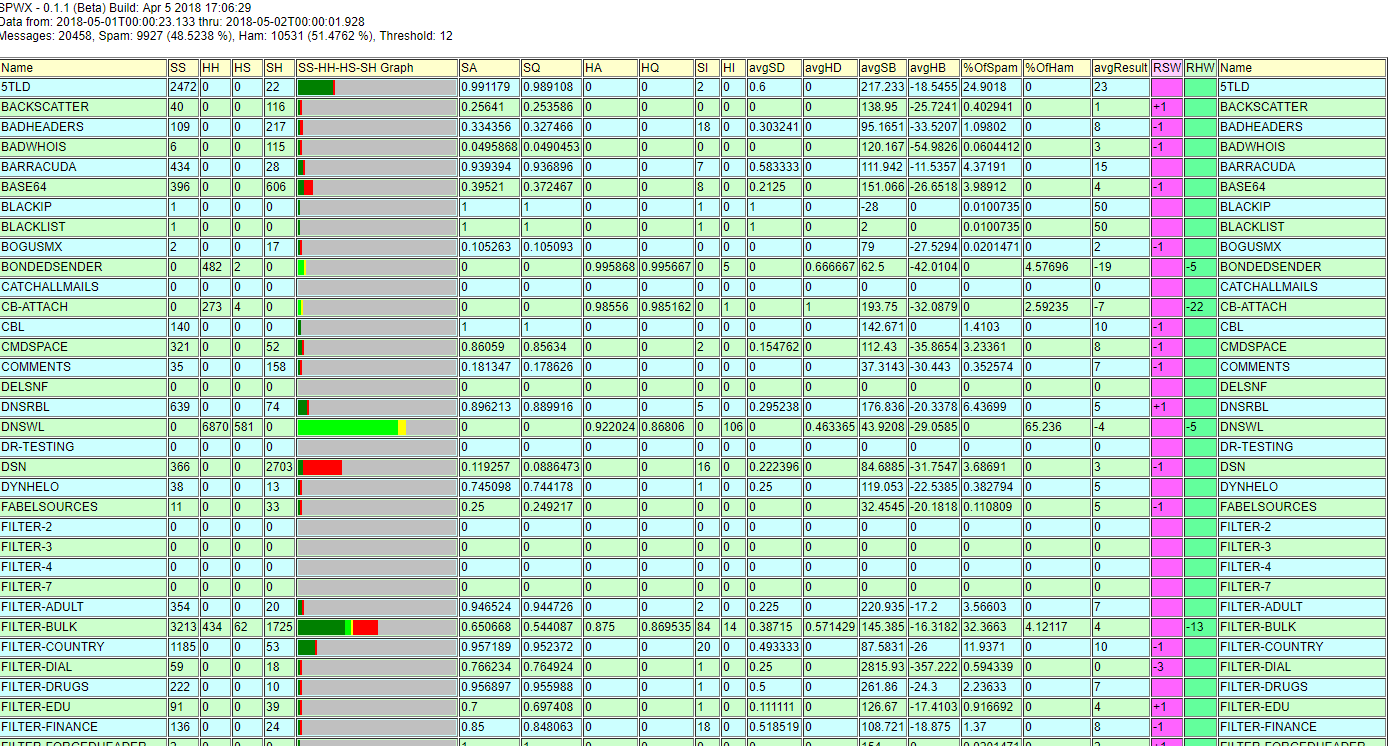
Name – Since there are a lot of columns the test name appears more than once. It’s on the left, and on the right. That makes it easier to match up with it’s numbers when you get to the “other side” of the chart.
SS – The number of times the test result and final result indicated spam. Test says Spam and result was Spam. We call this an accurate spam indication.
HH – The number of times the test result and final result indicated ham. Test says Ham and result was Ham. We call this an accurate ham indication.
HS – The number of times the test indicated ham, but the final result disagreed. Test says Ham, but the result was Spam. We call this a false negative.
SH – The number of times the test indicated spam, but the final result disagreed. Test says Spam, but the result was Ham. We call this a false positive.
SS-HH-HS-SH Graph – This column is a bar-graph representation of the SS, HH, HS, and SH numbers.
SA – Spam Test Accuracy. Any time a test provides a positive weight it is acting as a spam test. The accuracy of that test is a calculated as a Bayesian estimate of the probability that when the test fires the message is actually spam.
SQ – Spam Test Quality. If a spam test ever fires when the overall result disagreed (SH) then there is a possibility that this was a false positive — but it’s not certain! In order to get a better idea of how likely a SH event was actually a false positive we turn to Bayes again and estimate that probability. Then we start with the accuracy and reduce it by the probability of a false positive. P(SA) * (1 – P(FP)). If the probability of a false positive is low then the quality of the spam test will be very close to it’s accuracy. As the probability of a false positive gets higher the estimated quality of the test gets lower.
HA – Ham Test Accuracy. Any time a test provides a negative weight it is acting as a ham test. The accuracy of that test is calculated as a Bayesian estimate of the probability that when the test fires the message is actually ham.
HQ – Ham Test Quality. If a ham test ever fires when the overall result disagreed (HS) then there is a probability that this was a false positive. Again, not a certainty — and watch out for the terminology. We’re talking about a ham test here so in this case a false positive is when the test says it ham but it turns out to be spam. Most of us are used to thinking the other way around. Here again we take the Bayesian estimate of an accurate result (HA) and use the probability of a false positive to reduce that number. P(HA) * (1 – P(FP)). (See the SQ paragraph if you’re confused, then apply the same logic as if you were trying to detect ham instead of spam.
SI – Spam Test Importance. How many times did the spam test fire where if it hadn’t the overall result would have been different. Much of the time multiple spam tests will fire and the weight will be very high. If that weight is high enough then it’s likely that any individual test might not matter very much — because if it didn’t fire the end result still would have been high enough to classify the message as spam. The “importance” counts the number of times that the test really mattered — where if it hadn’t fired the total weight would have been below the threshold. This matters because if you have an accurate test that is never important then maybe there is room to push it’s weight a bit higher. That way, when the test senses something that the other tests don’t it might push the weight over the top.
HI – Ham Test Importance. How many times did the ham test fire where the total weight would have moved to the other side of the threshold if it had not fired. This is just like SI (above) but going in the negative direction.
avgSD – Average Spam Test Dominance. We want the weight of a test to be high enough that it’s important some of the time, but we don’t want it to be so important that it dominates all of the other tests. Put another way, if the test’s weight is too high then it might swamp out the results of the other tests. Dominance is a comparative measure of that. All other things being equal you probably want your most accurate tests to have the same average dominance and you probably want that to be a pretty high value depending upon the test quality. If you find that a single test is pushing down the dominance of your other high quality tests then you probably want to re-balance the weights a bit so that the other accurate tests can have more of a say.
avgHD – Average Ham Test Dominance. This is exactly the same as avgSD but working in the negative direction. (see above).
avgSB – Average Spam Test Balance. This is the average weight of each message where the overall result was spam (above the threshold) with the weight of this particular test taken out. It can give you an idea what the other tests were saying any time this test fired and the overall result was spam.
avgHB – Average Ham Test Balance. This is the average weight of each message where the overall result was ham (below the threshold) with the weight of this particular test taken out. So, for example, if a pure spam test fired but the overall result was ham then you would expect the avgHB to be negative enough to push the total weight below the threshold even with the weight of this test added in.
%OfSpam – Percent of Spam Accurately Tagged. As a percentage, how often did this spam test fire when the overall result was spam. This is a good measure of how much this test contributed to spam results.
%OfHam – Percent of Ham Accurately Tagged. As a percentage, how often did this ham test fire when the overall result was ham. This is a good measure of how much this test contributed to ham results.
avgResult – The average weight contributed by this test. Some tests are purely spam tests and only contribute a positive weight. Similarly some tests are purely ham tests and only contribute a negative weight. For a pure test the average weight will be exactly the weight configured for the test. However, some tests do have a positive and negative side. For those tests the average will depend on how often the test fires positively, how often it fires negatively, and the weights of each result.
RSW – Recommended Spam Weight. There is a complex calculation that attempts to recommend changes to the current weights. This calculation tries to recommend small changes to the existing weights in order to improve the overall accuracy of the system. It’s a very experimental computation, but it can sometimes nudge you in the right direction if you’re willing to try it.
RHW – Recommended Ham Weight. This is the experimental suggestion for the ham weight of a test.